dementiy 13.03.2010 00:36
Coding — Управление процессами в Linux
Хочу рассказать в общих чертах об управлении процессами в Linux. Итак...Может показаться, что в вашей системе все процессы выполняются одновременно, но это иллюзия, которую создает планировщик задач (sheduler). Планировщик задач отвечает за распределение процессорного времени между всеми процессами в системе.
Планировщик не представлен в виде какой-то одной функции, которая выполняла бы всю работу, но есть главная функция — schedule(), она определена в файле kernel/sched.c:
префикс __sched используется для функций, которые потенциально могут вызывать планировщик, в том числе и для самой функции schedule().
В schedule() выбирается очередь выполнения (в старых версиях планировщика, таких как O(1)-scheduler, очередь содержала списки задач, которые обслуживались по принципу FIFO - First Input First Output), которая связанна с конкретным процессором в системе (если процессор один, то и очередь всего одна) и из очереди выбирается следующий наиболее подходящий процесс на выполнение.
Как уже было сказано, с каждым процессором связана своя очередь выполнения (run queue, см. рис. 1).
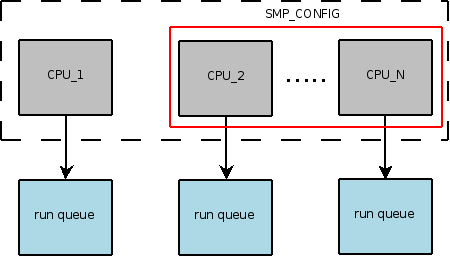
Рис.1. Каждому процессору соответствует своя очередь выполнения
Очередь описывается структурой struct rq, которая определена в файле kernel/sched.c:
1 |
struct rq {
|
curr указывает на текущую выполняемую задачу;
idle указывает на idle процесс, работает, когда нет ни одной другой готовой к выполнению задачи;
cpu это номер процессора, с которым связана данная очередь;
cfs очередь выполнения CFS (Completely Fair Scheduler);
rt очередь выполнения RT (Real-Time).
процессы реального времени отличаются от обычных процессов приоритетом. Для процессов реального времени приоритеты находятся в диапазоне от 0 до 99, а для обычных процессов в диапазоне от 100 до 139. Чем меньше значение приоритета, тем выше сам приоритет (важность задачи).
В ядре Linux, начиная с версии 2.6.23, были введены классы планирования (schedule class). На сегодняшний день (для версии ядра 2.6.32) можно выделить два основных класса (есть третий для idle):
CFS schedule class — отвечает за работу с обычными процессами (kernel/sched_fair.c);
RT schedule class — отвечает за работу с процессами реального времени (kernel/sched_rt.c).Каждый процесс принадлежит только одному классу, который несет ответственность за управление этим процессом. Информация о том, какой класс управляет процессом хранится в виде указателя на класс в дескрипторе процесса:
include/linux/sched.h:
1 |
|
Структура класса определена в файле include/linux/sched.h и содержит в себе указатели на функции, такие как, например, включение и исключение из очереди выполнения:
При создании нового процесса происходит вызов функции sched_fork() из copy_process() (описанной в прошлых статьях), в которой определяется к какому классу принадлежит процесс:
kernel/sched.c:
1 |
void sched_fork(struct task_struct *p, int clone_flags)
|
include/linux/sched.h:
1 |
#define MAX_USER_RT_PRIO 100
|
Если приоритет процесса больше 99, то устанавливается принадлежность процесса к классу CFS, который будет отвечать за управление этим процессом.
В зависимости от класса, к которому принадлежит процесс, он будет находиться в той или иной очереди выполнения — cfs_rq или rt_rq (см. рис. 2).
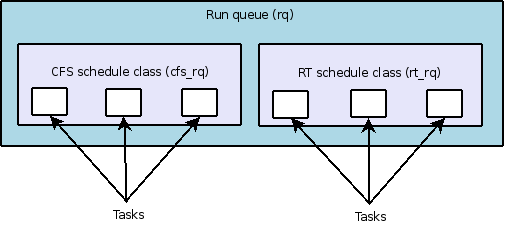
Рис.2. Схематичное представление очереди
Возвращаясь к функции schedule() было сказано, что выбирается наиболее подходящий процесс на выполнение:
kernel/sched.c (в функции schedule()):
1 |
|
kernel/sched.c:
Если количество процессов готовых к выполнению в общем равно количеству процессов принадлежащих к cfs_rq (rq->nr_running == rq->cfs.nr_running), то следовательно они все принадлежат к очереди cfs_rq и следующий процесс на выполнение будет выбираться по алгоритму CFS. В противном случае проходятся все классы, начиная с sched_class_highest (на самом деле это rt_sched_class), пока не будет выбран новый процесс на выполнение (см. рис. 3).

Рис. 3. Обход классов в поиске процесса
говоря о очереди выполнения cfs_rq, следует иметь ввиду, что на самом деле «очередь» представляет собой красно-черное дерево процессов, где самому левому листу дерева соответствует наибольший приоритет. Более подробно на сайте ibm
И последнее о чем хотелось бы еще сказать. Для многопроцессорных систем (SMP — Symmetric Multiprocessing) в планировщике реализована специальная функция load_balance() (kernel/sched.c), которая предназначена для того, чтобы процессор не только не «простаивал» (например, если его очередь пуста), но и как следствие, чтобы снизить нагрузку на другой процессор. Реализуется это за счет перемещения задач между очередями выполнения:
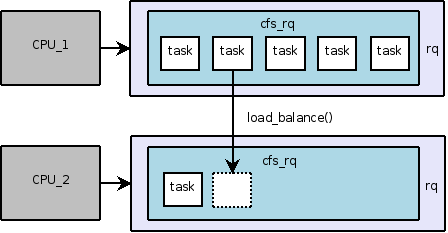
Рис. 4. Перемещение задачи из одной очереди в другую
P.S. Описано конечно же не все, а лишь малая часть, но как было сказано в самом начале преследовалась цель описать тему лишь в общих чертах.
P.P.S. И как всегда pdf'ка
 Похожие
Похожие Поделиться
Поделиться warchief 13.03.2010 01:05 #
warchief 13.03.2010 01:05 #
+ 0 -
Спасибо, жду следующую статью.
 exelens
exelens Vzlom
Vzlom digiwhite
digiwhite
Структура класса определена в файле include/linux/sched.h и содержит в себе указатели на функции (методы класса), такие как, например, включение и исключение из очереди выполнения
Так-как разговор идет в контексте языка C, то я бы исключил упоминание таких понятий как "методы класса", дабы не вводить никого в заблуждение. Нету в C классов как таковых. Ну или используйте вместо этого "функции-члены" тогда.
 dementiy
dementiy
А я решил, что так может быть понятней будет, проведя некоторую аналогию с С++ (да и другими языками, в которых есть понятие класса), но раз может возникнуть некоторая неопределенность, то тогда убираю.
Отдельно данный вопрос освети для с++ Думаю будет полезно и правильно =)
Я не совсем понял, что имелось ввиду. Я хотел сказать, что в С++ (как и в других объектно-ориентрированных языках) есть понятие класса, данные которого называют методами.
Было бы еще интересно для, так сказать, "самодостаточности" статьи добавить краткое описание функции likely :).
В двух словах: likely означает вариант, который имеет большую вероятность для выполнения. В дальнейшем при компиляции будет проведена, некоторая оптимизация ассемблерного кода. Так же есть unlikely, то же самое, но наоборот, то есть менее вероятный вариант. likely и unlikely являются макросами, которые определены в файле inlude/linux/compiler.h
Посмотрел туда... жостко конечно. Что-то понять мне там особо не удалось :(
На самом деле это рюшечки GCC. Здесь (правда на английском) в разделе "Optimization extensions" можно немного прочитать про них. Либо уже смотреть в документацию GCC.
 kstep
kstep h0rr0rr_drag0n
h0rr0rr_drag0n
Спасибо, было интересно! :-)

